Data Settings for File Drop
Data Settings control how File Drop parses incoming files and how that data is mapped to the label.
Accessing Data Settings
- Open your File Drop template
- Click Settings dropdown
- Select Data Settings
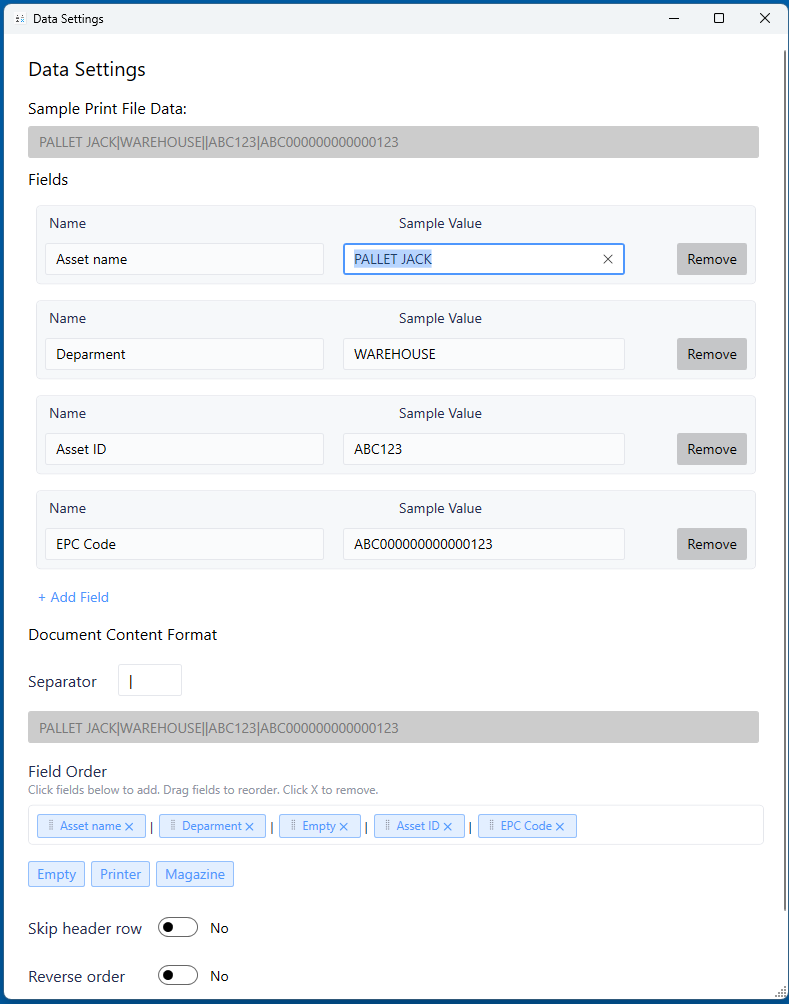
Understanding Your Data Format

Sample Flat File
Example: PALLET JACK|WAREHOUSE|ABC123|ABC12300000000000123
Components:
- Data fields: 4 Containers of data
- Separator:
|Pipe - Order: Fixed sequence
Field Order Mapping
Critical Step: Match field order to data order!
Place the Field order tokens in the exact same order as the data file. So the first token represents the first field in the file, and so on.
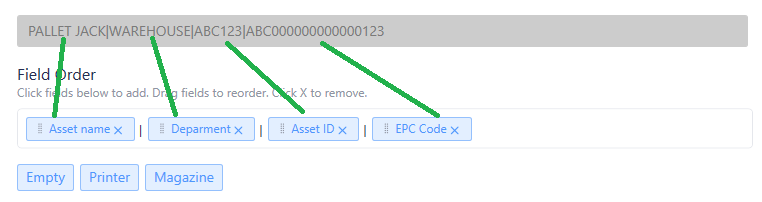
If there are fields for printer selection, and or Magazine selection, place those to match their position in the spreadsheet.
Additional Options
Skip Header Row
Select this option if the data file contains a header row. This prevents that data from printing on a label.
Reverse Print Order
Flips the output sequence of labels.
Normal: Prints labels in file order (top to bottom) Reversed: Prints labels in reverse order (bottom to top)
Testing Your Configuration
Create Test File
- Copy Sample Print File Data string
- Create new .txt file
- Paste string
- Save to watch folder
- Verify label prints correctly
Multiple Records
Multiple records can print from 1 file. The example below would print 3 labels, one for each line.
S22-1234,A1,H&E,BILLY BOB,DR JONES
S22-1235,B1,Trichrome,JANE DOE,DR SMITH
S22-1236,C1,PAS,JOHN SMITH,DR BROWN
Need Help?
- Phone: 800-650-0632
- Email: Support@QRlogix.com